
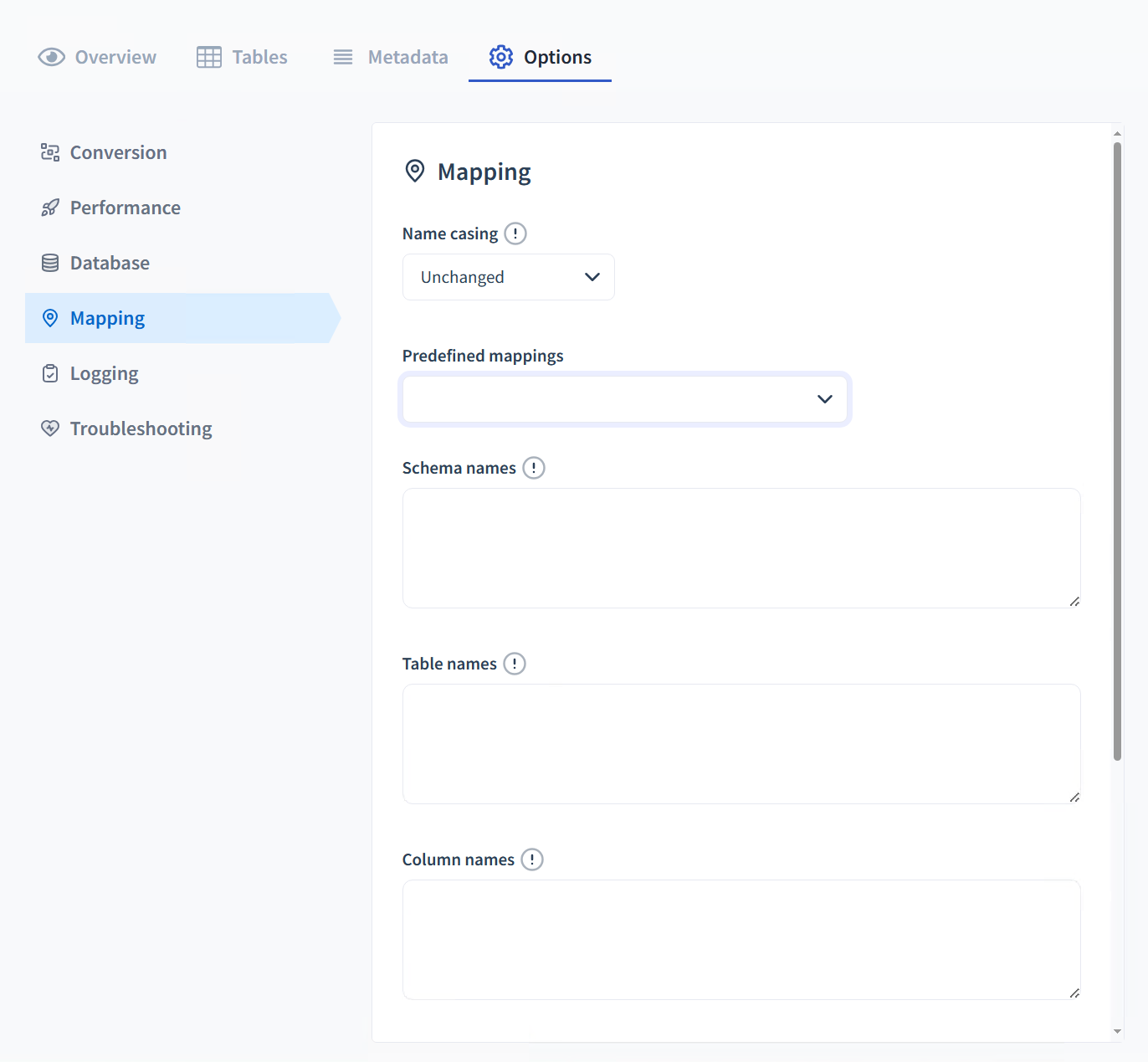
Mapping
Note: The mapping below is applied to all tables. You can override the mapping for specific table by going to the Tables screen and opening the table details screen via the Details button next to the table name.
Name casing
By default, we case the table names in the target in such a way to avoid the need to quote names when running SQL queries. If you wish to preserve the source casing, or force upper or lower case, you can change the default behavior.
Predefined mappings
Db as Schema prefix This setting will prefix the schema names with the database name, helping to preserve the origin of the schema when the database name is crucial for identification.
Db as Schema, Schema as Table prefix Here, the original database name becomes the schema name, and the original schema name is used as a prefix for table names, which is useful when merging multiple databases into a single schema.
Alias as Schema prefix With this option, an alias defined within the migration tool is used as a prefix for the schema names, allowing for customization and easier identification in the target system.
Alias as Schema, Schema as Table prefix This choice takes an alias for the database name and uses it as the schema name, while the original schema name is prefixed to the table names, maintaining a clear structure when the original database name should not or cannot be used directly.
Schema names
The Schema names section in database migration settings lets you define rules to translate schema names from the source to the target database using a "SOURCE=TARGET" format. The tool processes only the first rule that matches each schema and supports placeholders like {db} for the database name, {alias} for database alias, {schema} for the schema name, and {table} for the table name, which will be automatically replaced with the actual names during the migration.
Table names
Allows for the specification of renaming rules from source to target databases, using the "SOURCE=TARGET" syntax, with only the first applicable rule being executed per table. It supports placeholders such as {db} for the database name, {alias} for the database alias, {schema} for the schema name, and {table} for the table name, which are dynamically replaced with their corresponding values during the migration.
Column names
In the Column names configuration, you can establish renaming conventions for columns by creating "SOURCE=TARGET" rules. The system will apply only the first matching rule for each column, disregarding subsequent matches.
Datatype mapping
Omni Loader will always map data types in such a way that data is not lost and that the target type is as close to the source type as possible. You can opt to change the way we map the data types, by forcing the whole type to be changed or just a length of the type.
Default value mapping
Comment table column default values are automatically translated from source into the target equivalents. If you have complex default value expression we can't handle, you can define the correct target default value here and it will be applied for all columns of all tables.
Last updated